STL容器

文章目录
本文主要记录STL容器的使用笔记。
值语义
插入容器的元素通过copy或者move保存值,在删除的时候销毁元素、释放值。
array
静态数组,对C风格数组简单封装。
size是元素个数,不用像C那样 #define DIM(a) (sizeof(a)/sizeof(a[0])) 定义宏。
可以当成定长vector来使用,比C风格数组更好用。
如果元素是基本类型(非class),那么默认是没有初始化的(除非是静态存储)。
因此需要使用初始化列表或者赋值进行初始化。
|
|
vector
动态数组。内部存储空间是连续的,不够时会realloc(有复制的性能开销)。
查询速度快,但修改(插入、删除)只有在后端才快。
如果能够预估容量,在构造函数或者reserve方法指定大小能够提高性能。
另外需要注意reserve只是预分配内存,并不初始化内存,直接访问可能会导致运行时错误。
删除指定元素习惯用法是erase+remove:
|
|
vector<bool>
特殊优化的vector,按位存储数据,可以当成bitmap来使用,最大位数可动态改变。
最大位数固定的话,也可以使用 bitset 。
适合存储标志位,比如说判断数值是否设置/存在,在特定情况下比unordered_set更快、更省空间。
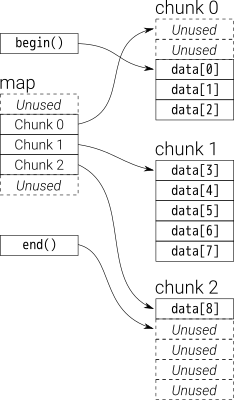
deque
双端队列,可以在前后端快速插入或取出数据。
内部存储是多块定长数据块拼接的,空间不足不需要像vector那样realloc复制旧数据。
有点类似于vector of vector,简单来说就是数据块指针数组。
在空间不足的时候(比如说push_font),可能会有数据块指针的复制(不是数据块复制)。
queue
queue
先进先出队列。
默认通过deque实现,不需要reserve空间。
pop没有返回值,丢弃前端第一个元素(也就是front)。
如果front赋值给引用变量,在pop之后就不能使用了。要么用完再pop,要么复制一份。
priority_queue
优先队列。
默认通过vector+大堆算法操作实现,最大元素在队头(pop的时候会移到队尾)。
默认比较函数是less<T>,有点反直觉,原因大概是因为STL各种算法默认使用less(比如说sort)。
自定义比较函数时,需要注意第三个模板参数是类型名,可以参考下面的示例:
|
|
相对而言仿函数的写法比较简单,而且适用于STL中各种容器和算法。
stack
后进先出数据存储。
默认通过deque实现,不需要reserve空间。
pop没有返回值,丢弃栈顶元素(也就是top)。
如果top赋值给引用变量,在pop之后就不能使用了。要么用完再pop,要么复制一份。
大小堆
不算容器类,在stl算法类中实现。
Top N类需求或者优先队列(可以使用priority_queue)、定时器比较常用。
set
基于红黑树的set,内部有序(可有序遍历)。
通常比unordered_set要慢。
set
存储不重复数据的集合。
multiset
可存储重复数据的集合。
unordered_set
基于哈希表的set,无序但比set性能更优。
另外要求值类型要有对应的hash函数。自定义hash函数可以参考下面的代码:
|
|
函数指针或者lamda也可以,不过写法比较麻烦,所以还是尽量用仿函数。
unordered_set
unordered_multiset
map
基于红黑树的map,内部有序(可有序遍历)。存储键值型数据。
通常比unordered_map要慢。
值类型是pair,first为键,second为值。
map
存储不重复键值型数据。
有重载[]运算符。
multimap
可存储重复键值型数据。
没有重载[]运算符,需要键值make_pair后insert。
unordered_map
基于哈希表的map,无序但比map性能更优。
另外要求key的类型要有对应的hash函数,自定义hash函数建议使用仿函数方式。
list
双向链表。
在有节点迭代器时插入、删除操作比较快。
缺点是不能根据位置直接访问,需要遍历才行。
与哈希表配合使用,可以实现一些操作在O(1)的数据结构(比如说LRU,LFU)。
最后元素的迭代器可以通过end()自减获得。
通过 splice 可以实现链表(不同或同一链表皆可)节点的转移。
STL内部实现一般是循环链表,通过一个代表end的内部节点管理。
链表迭代器可以简单理解为拥有指向节点指针的对象。
forward_list
单向链表。
类似双向链表,只能正向遍历,比list节约空间。
bitset
bitmap,按位(bit)存储数据,节省空间,特别适合标志位存储。
bitset最大位数是编译时确定的,如果需要动态大小可以使用 vector<bool>。
另外bitset局部变量是分配在栈上,大小指定太大会导致栈溢出,需要通过new分配在堆上。
参考资料
- 《STL源码剖析》 by 侯捷
- EASTL
- cpp reference