C++中的memory order

文章目录
本文主要记录个人对C++中memory order的一点理解。
what
memory order指定(编译器和CPU)如何安排(当前线程)原子操作附近内存访问指令,以达到预期的同步效果。
memory order specifies how memory accesses, including regular, non-atomic memory accesses, are to be ordered around an atomic operation.
why
为什么需要指定memory order?
- 一般语句并不是原子操作
- 多线程访问共享变量没有限制则结果不确定
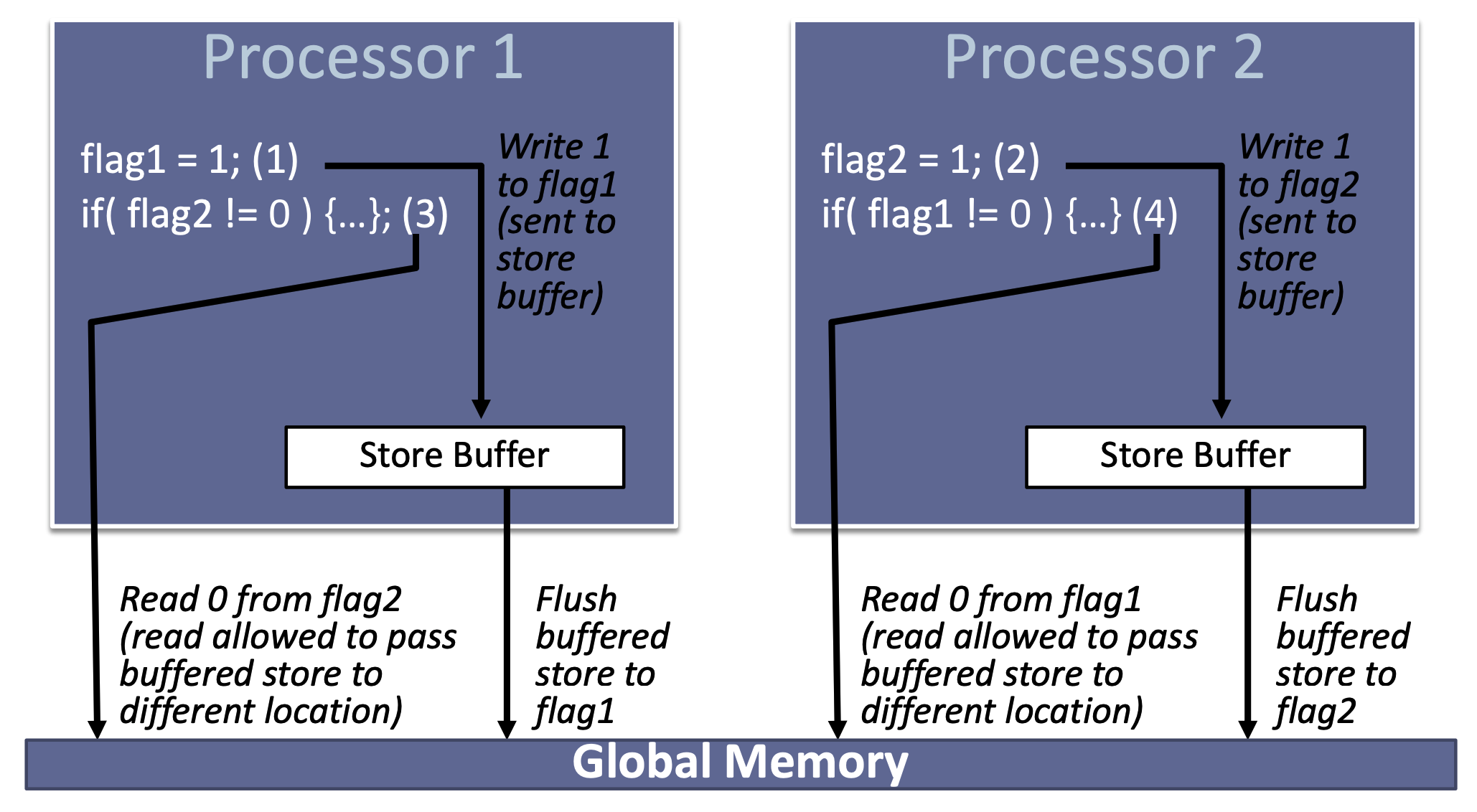
- 编译器或CPU可能出于优化目的调整指令执行顺序 (重要!)
- CPU cache导致不同核心不一定得到一致的内存数据 (重要!)
后面两条是理解不同memory order的关键。
类型
Relaxed ordering
这种排序比较宽松,主要确保是原子操作(简单理解为一条指令),不要求同步、其它读写没限制。
典型使用场景是计数器,比如说shared_ptr引用计数器的自增操作。
|
|
Release-Acquire ordering
| 取值 | 含义 |
|---|---|
| memory_order_release | no reads or writes in the current thread can be reordered after this store. All writes in the current thread are visible in other threads that acquire the same atomic variable. |
| memory_order_acquire | no reads or writes in the current thread can be reordered before this load. All writes in other threads that release the same atomic variable are visible in the current thread |
| memory_order_acq_rel | read-modify-write操作: acquire + release |
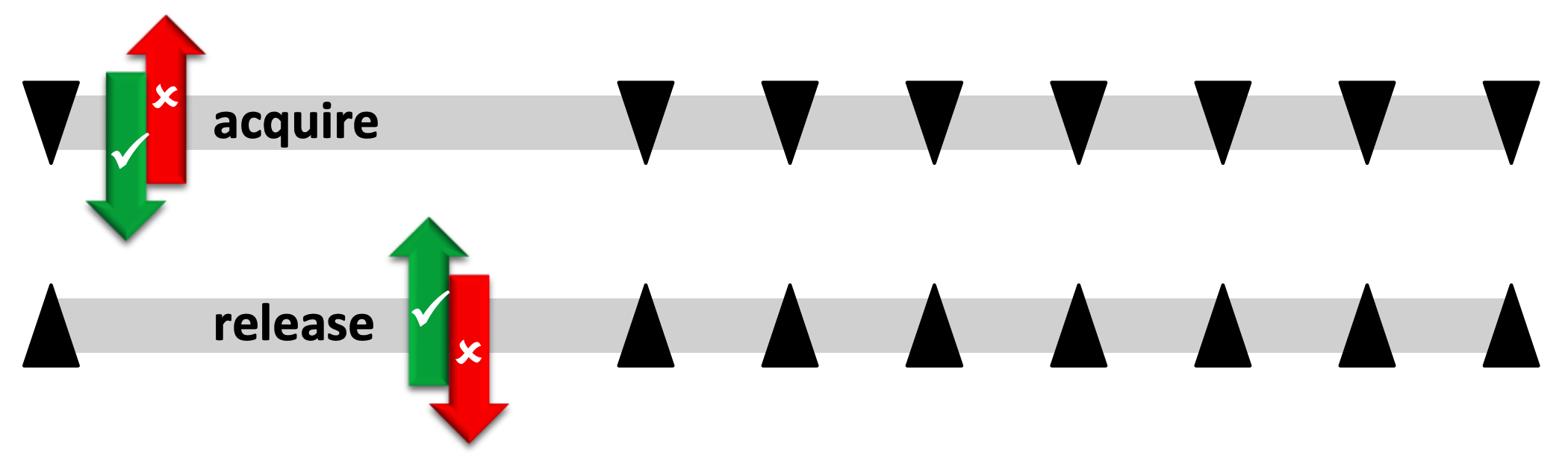
memory_order_release限制当前线程store操作之前的读写(指令)不能重排到store后面执行。
memory_order_acquire限制当前线程load操作之后的读写(指令)不能重排到load前面执行。
副作用是线程A的store操作之前的所有写对于load到该值的线程B是可见的。
也就是说线程B和线程A之间(不保证其它线程同步!重要!)同步了内存(线程A在store前的写入)。
该内存模型下的原子操作就好比内存同步点,写入和读取到同一原子变量值的两个线程间进行了内存同步。
shared_ptr引用计数器自减需要memory_order_acq_rel,这样多线程同时析构才会知道最新值。
常见的互斥锁、自旋锁就是这种释放、获取的内存访问同步模式。
|
|
Release-Consume ordering
| 取值 | 含义 |
|---|---|
| memory_order_release | no reads or writes in the current thread can be reordered after this store. Writes that carry a dependency into the atomic variable become visible in other threads that consume the same atomic. |
| memory_order_consume | no reads or writes in the current thread dependent on the value currently loaded can be reordered before this load. Writes to data-dependent variables in other threads that release the same atomic variable are visible in the current thread. |
memory_order_release限制当前线程store操作之前原子变量依赖的读写(指令)不能重排到store后面执行。
memory_order_consume限制当前线程load操作之后依赖原子变量的读写(指令)不能重排到load前面执行。
与Release-Acquire ordering类似,不过副作用没那么大。
线程A中只有原子变量依赖的前置写才对给load到值的线程B中依赖原子变量的后置读可见。
不过目前规范不推荐使用,了解即可。
|
|
Sequentially-consistent ordering
| 取值 | 含义 |
|---|---|
| memory_order_seq_cst | 不允许重排+所有seq_cst原子变量写入顺序对于相关线程来说都是一致的 |
限制性最强、对性能有些影响、标准库默认使用的memory order。
可以认为是代码顺序+原子变量运行时的写入顺序(唯一,就像所有线程以某种顺序依次运行)。
所有seq_cst原子操作就好比内存同步点,所有线程保持内存一致。一般需要用到内存屏障指令。
下面的例子只有使用memory_order_seq_cst才能保证线程c和d观察到一致的原子变量x和y的修改顺序。
要么都是x先改y后改,要么都是y先改x后改,不可能线程c观察到x先改y后改、线程d观察到y先改x后改。
Any other ordering may trigger the assert because it would be possible for the threads c and d to observe changes to the atomics x and y in opposite order.
|
|
总结
原子操作就好比内存同步点,只是不同的memory order同步数据的多少和范围不一样。
有的根本不(需要)同步,有的两线程间同步前置写,有的两线程间同步依赖写,有的所有线程间同步写入。
与volatile的关系
volatile只是对当前线程有效,对多线程无效(无限制),而且不是原子操作。