数据库之redis

文章目录
本文主要介绍工作项目中经常使用的数据库—— redis 。
安装
如果需要通过systemd开机启动,确保安装对应开发包。
|
|
如果编译不通过大概率是GCC版本低,可以参考 编译安装GCC7.2.0 操作。
配置
根据需要修改配置文件。
- 后台运行
1daemonize yes - 设置密码
1requirepass 密码 - 远程连接
1 2# bind 127.0.0.1 protected-mode no
开机启动
配置文件修改supervised:
|
|
增加redis-server.service
|
|
内容如下,注意redis-server路径和配置文件路径:
|
|
保存之后启动服务:
|
|
数据类型
使用
具体参考官方说明 Redis data types。
内部实现
可以参考张铁蕾的 Redis内部数据结构详解。
其中sds、dict和skiplist值得深入学习。
- sds
sds一般用来存储string。
sds包括header和字节数组,而header包括长度(len)、容量(alloc)和标志(flags)。
header有5种类型,sdshdr5稍微特别一点,其它类型就是长度和容量字节大小(1,2,4,8字节)不一样。
sds指针实际上指向字节数组,通过前一个字节(flags)得知header类型,进而得到长度和容量信息。
实际存储会预留一定的空间,一般是翻倍,最多预留SDS_MAX_PREALLOC(1MB)。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16typedef char *sds; /* 实际指向buf */ struct __attribute__ ((__packed__)) sdshdr5 { unsigned char flags; /* 3 lsb of type, and 5 msb of string length */ char buf[]; }; struct __attribute__ ((__packed__)) sdshdr8 { uint8_t len; /* used */ uint8_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[]; }; struct __attribute__ ((__packed__)) sdshdr16 {...} struct __attribute__ ((__packed__)) sdshdr32 {...} struct __attribute__ ((__packed__)) sdshdr64 {...}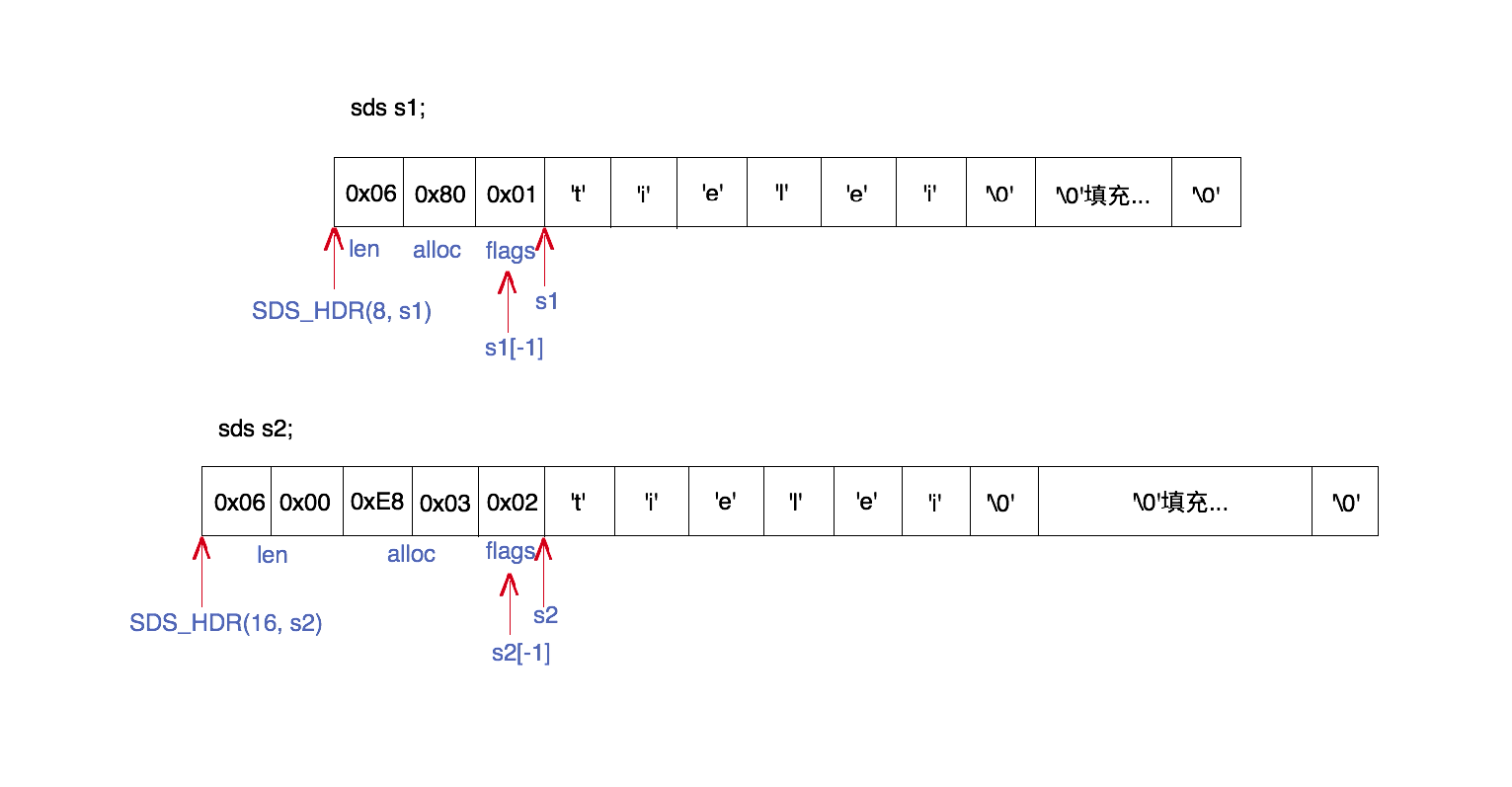
- dict
开链法哈希表实现,自动扩容时会增量重新哈希。
重新哈希操作分散在查询、插入、删除中逐步完成。
哈希表的大小总是2的幂,重新哈希时有2个哈希表,其中一个的大小是另一个的2倍。
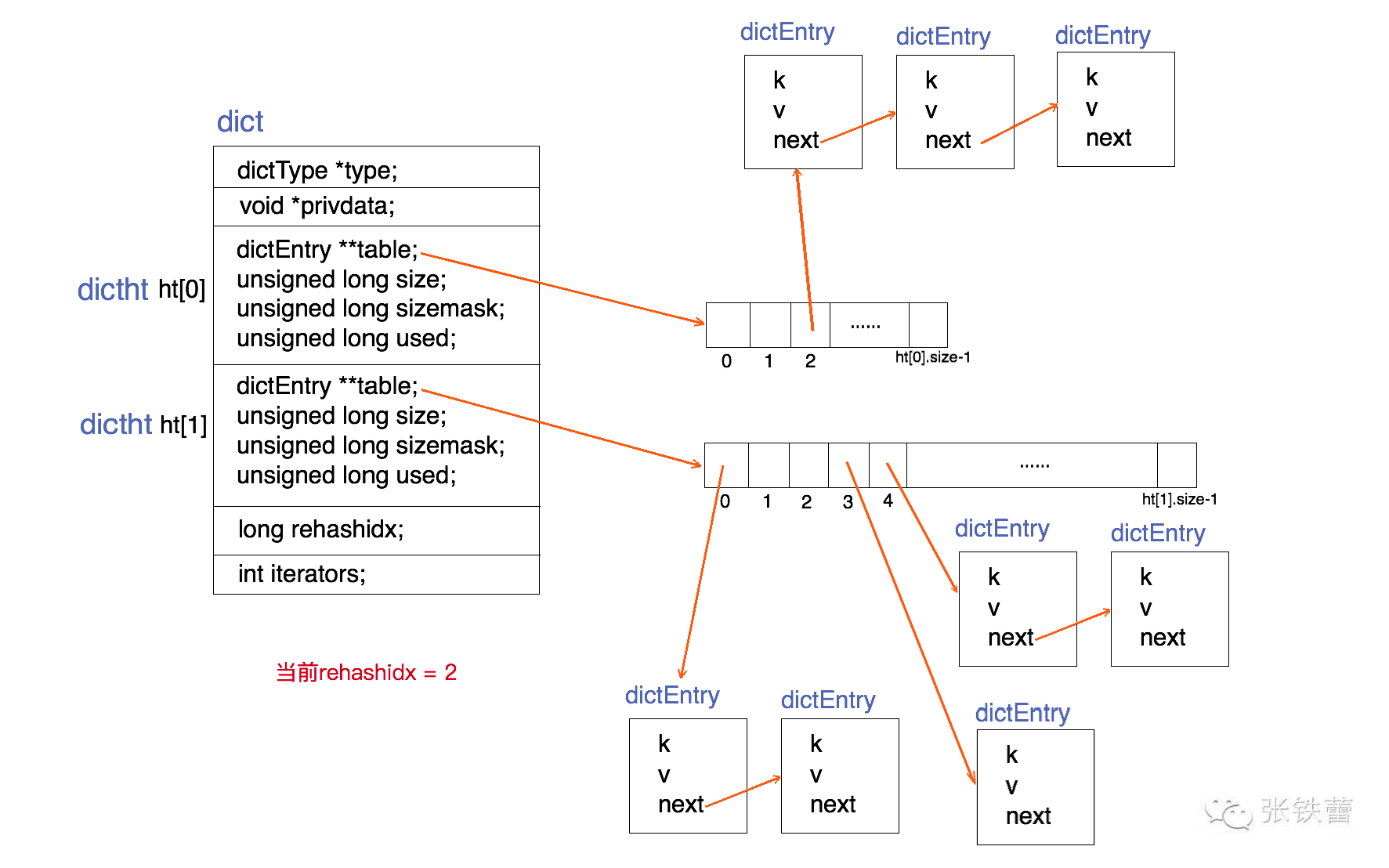
- skiplist
可以参考 跳跃表skiplist 的说明。 - ziplist
在连续内存空间上变长编码存储多个数据项的双向链表。
适合数据项较少且每项内存占用不大(64B)的场景。
ziplist:<zlbytes 4B><zltail 4B><zllen 2B><entry>...<entry><zlend 1B>
entry:<prevlen><len><data> - quicklist
节点是ziplist的双向链表。提高内存使用效率,减少内存碎片。 - intset
在连续内存空间按统一编码(3种)有序存储整数的数据结构。1 2 3 4 5 6 7 8 9typedef struct intset { uint32_t encoding; uint32_t length; int8_t contents[]; } intset; #define INTSET_ENC_INT16 (sizeof(int16_t)) #define INTSET_ENC_INT32 (sizeof(int32_t)) #define INTSET_ENC_INT64 (sizeof(int64_t))
持久化备份
具体参考官方说明 Persistence。
- RDB (Redis Database File)
fork进程在后台生成数据集快照(.rdb文件)。
可以手动或者自动触发(指定时间内发生指定写操作)。1 2 3save 900 1 save 300 10 save 60 10000 - AOF (Append Only File) 推荐
追加方式记录写操作到文件,类似于MySQL的binlog。
新版本还会自动重写,减小文件大小。1 2appendonly yes appendfsync everysec
多线程
命令执行仍然是单线程模型,多线程用于处理IO。
主从+哨兵
主从
一般是主机可读可写,多个从机只读。
从机通过slaveof设置其对应的主机:
|
|
哨兵
参考官方说明 High Availability。
哨兵至少3个,采用Raft算法选leader,监控主机并在其发生故障时自动切换主从。
应用
缓存
排行榜
sorted set的ZADD、ZRANGE 、ZRANK。
计数器
原子操作命令 INCRBY 。
限时场景
通过EXPIRE设置键的超时时间,适合限时优惠券、验证码等场景。
分页与模糊搜索
ZRANGE key min max BYLEX [LIMIT offset count] 。
比如说ZRANGE movies - + BYLEX LIMIT 0 10,BYLEX可以按内容的词典序排序。
相互关系存储
比如说点赞、好友关系(共同好友)。
set的SADD、SISMEMBER、SINTER。
最新列表
list的LPUSH、LTRIM、LRANGE。
大数据位操作
参考官方说明 Bitmaps。
bitmap的SETBIT、GETBIT、BITCOUNT。
适合签到、判断是否在线等场景。
简单消息队列
参考官方说明 Pus/Sub 。
秒杀类活动
单例的情况,使用SET命令与NX、PX选项实现。
业务逻辑复杂一点的,还可以使用 lua脚本 实现原子操作。
集群的情况,不是很推荐使用分布式锁(高并发性能不高)。
削峰、限流和分库分表更为重要,最终转化为单例的情况。
削峰可以通过消息队列缓冲,在时间上分散请求。
限流可以过滤短时间内重复请求,只允许预约过的用户,限制并发请求量。
分库分表可以分地区分商品分库存等。
分布式锁
个人认为分布式锁适合低频使用的场景,比如说选主、服务发现之类的。
具体参考官方说明 Distributed locks 。
单例获取、释放锁
- 申请
1SET 资源名称 足够唯一的随机值 NX PX 锁的自动释放时间足够唯一的随机值是指所有客户端获取锁请求中唯一。
一种可能的实现是随机值、客户端ID和时间戳的组合。 - 释放
1 2 3 4 5if redis.call("get",KEYS[1]) == ARGV[1] then return redis.call("del",KEYS[1]) else return 0 end释放锁的时候需要键和值都匹配。
Redlock算法
获取锁步骤:
- 获取当前毫秒级别时间
- 以相同键值顺序获取所有实例(N个)的锁,超时时间要小于锁的自动释放时间
- 计算获取锁的总耗时,小于锁的自动释放时间且超过一半(N/2+1)实例获取锁成功才算真正成功
- 真正获取锁成功后,锁的有效时间就是自动释放时间减去步骤3计算的总耗时
- 如果没有真正获取到锁,那么需要释放所有实例的锁
没有真正获取到锁,客户端可以延迟随机时间之后重试。
释放锁就简单的多,释放所有实例的锁即可。